Failing to Explore: Language Models on Interactive Tasks
Language models are powerful—but they are not search algorithms.
When placed in interactive environments where solutions must be discovered rather than recalled, they exhibit a consistent and surprising weakness: they fail to explore.
📖 Overview
We study language models in settings where they must interact with an environment over multiple steps, receiving feedback and adapting their queries. The objective is not to produce a single answer, but to discover the best possible outcome within a limited interaction budget.
Across a range of controlled tasks, we find that models systematically:
- commit too early to suboptimal solutions,
- rely on local refinements rather than global search,
- and fail to meaningfully improve with additional interaction steps.
As a result, they consistently underperform simple, non-learned exploration strategies.
🧠 From Reasoning to Search
Most evaluations of language models assume that the solution is reachable through reasoning alone. In contrast, many real-world problems require search under uncertainty, where the model must actively explore the space of possibilities.
We formalize interaction as a sequential process: at each step, the model proposes a query, receives feedback from the environment, and updates its behavior. The goal is to maximize the best reward observed across all steps, making this fundamentally an exploration problem.
🧪 A Testbed for Exploration
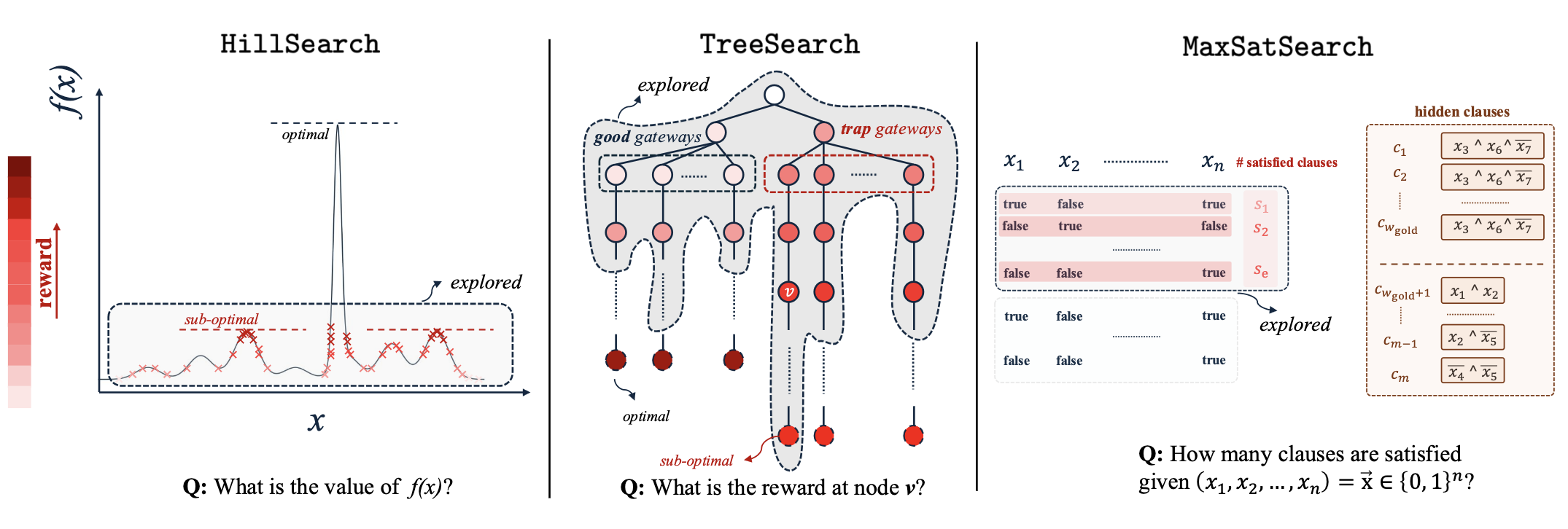
To isolate exploration from other confounding factors, we design three environments with controllable difficulty.
HillSearch models continuous optimization. The reward function contains many local maxima and a single narrow global optimum. Success requires exploring widely rather than refining early guesses.
TreeSearch introduces sequential structure. Some branches yield high rewards early but perform poorly overall, while others require patience before paying off. The task tests whether the model can avoid being misled by early signals.
MaxSatSearch captures combinatorial reasoning. A hidden clause dominates the objective, but cannot be discovered through local edits alone. The model must identify global structure rather than incrementally improving candidates.
📉 What Goes Wrong
Across all three tasks, the same failure pattern emerges.
Models tend to latch onto early promising signals and commit prematurely. Once committed, they focus on local improvements, rarely revisiting alternative regions of the search space. Increasing the interaction budget does not resolve this—instead, it amplifies inefficient behavior.
These tendencies manifest differently across tasks:
- in continuous settings, models converge to local optima,
- in structured environments, they follow a single branch too deeply,
- in combinatorial tasks, they make small edits without discovering the underlying structure.
Despite their sophistication, models behave like greedy optimizers, not adaptive explorers.
⚖️ A Surprisingly Strong Baseline
We compare language models against extremely simple heuristics: random exploration followed by local refinement, stochastic branching strategies, and random initialization with iterative updates.
These methods require no learning and minimal design. Yet across all tasks, they consistently outperform language models, often by a large margin. Moreover, they benefit significantly from increased interaction budget, highlighting how effectively they utilize additional opportunities for exploration.
🔧 Improving Exploration (Simple but Effective)
We test two lightweight interventions.
Parallel exploration splits the interaction budget across multiple independent runs and selects the best outcome. This significantly improves performance, even though it should not help under optimal exploration. In practice, it introduces diversity that the model itself fails to generate.
Periodic summarization replaces long interaction histories with structured summaries of explored regions, best solutions, and remaining gaps. This reduces the tendency to overcommit to past decisions and encourages broader search.
Both methods highlight a key limitation: models do not naturally maintain diversity or uncertainty over time.
📈 A Simple Explanation
Empirically, the probability of success grows sublinearly with the number of interaction steps:
[ q(x) \propto x^\alpha \quad \text{with } \alpha < 1 ]
This implies diminishing returns from longer trajectories. Instead of committing to a single run, it becomes more effective to explore multiple independent trajectories—a behavior that must currently be imposed externally.
🌍 Implications
This limitation extends beyond synthetic benchmarks. Any system that relies on language models for sequential decision-making is affected, including:
- tool-using agents,
- web navigation systems,
- program synthesis pipelines,
- and scientific discovery workflows.
All of these require efficient exploration under constraints, a capability that current models lack.
🧠 Takeaway
Language models can reason, but they do not search well.
They exploit what they find, rather than exploring what they do not know.
Bridging this gap will require more than scaling. It calls for explicit mechanisms for exploration, better memory management, and strategies that maintain diversity over time.
🔗 Links
- 📄 Paper: arXiv:2601.22345
📚 Citation
@misc{jafariraviz2026failingexplorelanguagemodels,
title={Failing to Explore: Language Models on Interactive Tasks},
author={Mahdi JafariRaviz and Keivan Rezaei and Arshia Soltani Moakhar and Zahra Sodagar and Yize Cheng and Soheil Feizi},
year={2026},
eprint={2601.22345},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2601.22345},
}
