Your LLM Agents are Temporally Blind: The Misalignment Between Tool Use Decisions and Human Time Perception
LLM agents are increasingly deployed in dynamic environments, yet they implicitly operate as if the world were static.
This paper identifies a core failure:
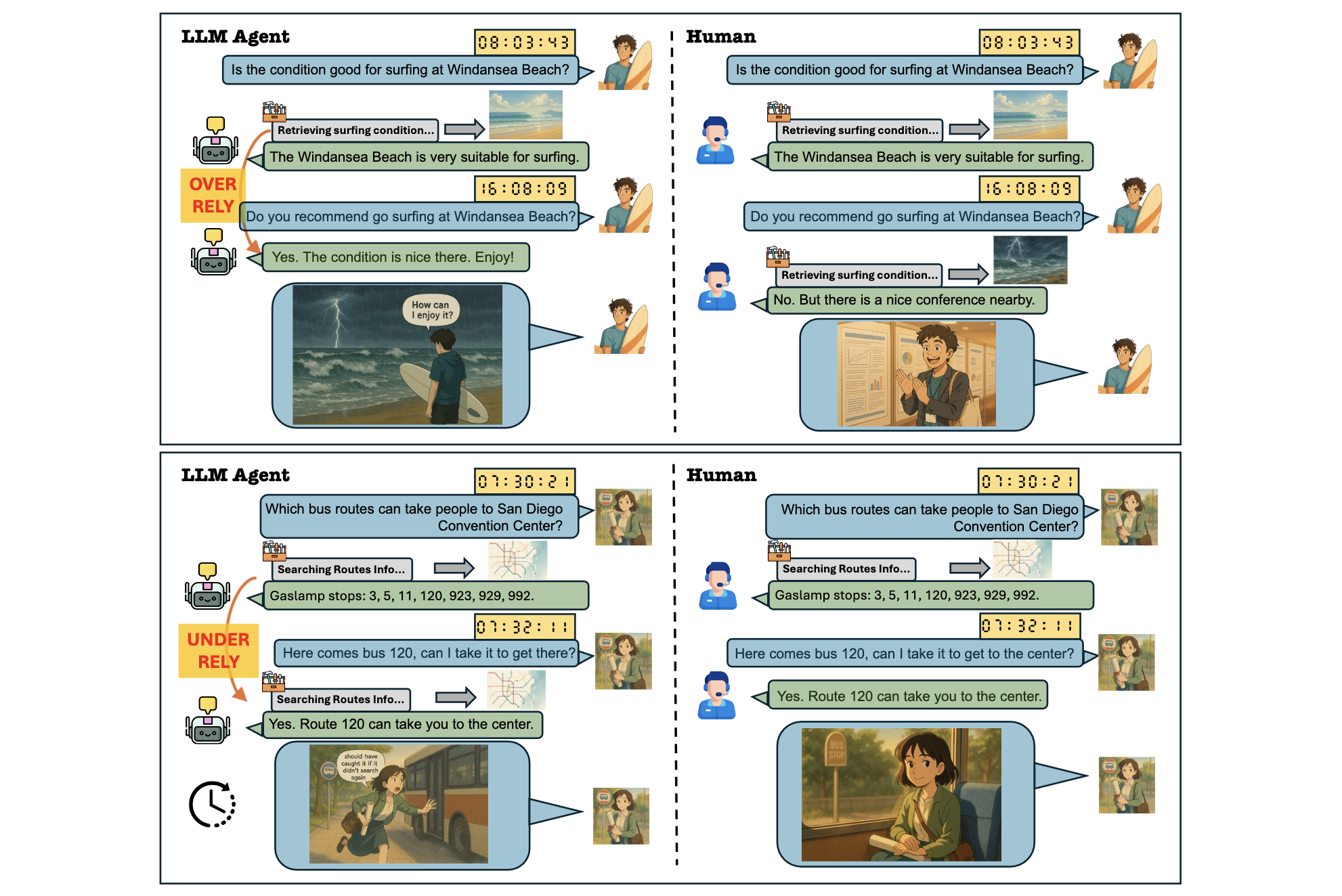
Temporal Blindness — models fail to account for real-world time elapsed between interactions when deciding whether to call tools.
As a result, tool-use decisions become misaligned with human expectations. Models either over-rely on stale information or under-rely by making redundant tool calls. To study this systematically, the paper introduces TicToc, a benchmark for time-aware tool use, and evaluates 18 models, revealing a persistent gap between agent behavior and human temporal reasoning. Prompting offers limited gains, while targeted post-training proves necessary.
🧠 Motivation
Tool use is not just about whether the model has access to information, but whether that information is still valid. Humans naturally incorporate time into their decisions: they reuse recent observations and re-check information that may have changed. In contrast, LLM agents often trust outdated context or unnecessarily repeat tool calls. Both behaviors degrade correctness and efficiency, highlighting that temporal awareness is a missing component of current agent design.
📊 TicToc
TicToc is designed to evaluate how well models align their tool-use decisions with human temporal judgment. It contains 1,864 multi-turn trajectories, which are expanded into 5,592 samples by varying the elapsed time before the final query. After filtering uncertain annotations, 3,016 high-confidence samples remain.
The dataset spans 76 scenarios with different temporal dynamics. These are grouped into three categories:
| Level | Description |
|---|---|
| Low | environments that are largely static |
| Medium | environments that change occasionally |
| High | environments that change rapidly |
Each scenario may be read-only (retrieval) or read+write (state-changing), ensuring coverage of both passive and interactive settings.
🔁 Interaction Structure
The dataset includes diverse interaction patterns that reflect realistic agent use. In read-only settings, the user may repeat a question, compare previously retrieved items, request details about a subset of earlier results, or ask a reasoning question that depends on past information. In read+write settings, interactions include retrying failed actions, confirming previous actions, repeating completed requests, or operating under changing resource constraints.
In all cases, correct behavior depends on whether previously retrieved information remains valid given the elapsed time.
⏱️ Modeling Time
Each trajectory is augmented with realistic timestamps that simulate user reading and writing speed, model generation time, and tool latency, with additional stochastic variation. To test temporal sensitivity, every trajectory is replicated with three different time gaps—small, medium, and large—inserted before the final user query.
Importantly, these gaps are context-dependent. A “large” gap in a high-frequency environment may correspond to minutes or hours, whereas in a static environment it may correspond to days or months.
👥 Human Preferences
Human annotators evaluate each scenario by choosing whether the agent should answer directly or call a tool, with optional lean preferences for uncertain cases. After filtering ambiguous samples, the dataset contains 1,112 cases where tool use is preferred and 1,904 where direct answering is preferred. Inter-annotator agreement is high (Krippendorff’s α = 0.857), indicating reliable judgments.
📏 Evaluation
Performance is measured using Normalized Alignment Rate (NAR), which captures how often a model’s tool-use decision matches human preference. A score of 50% corresponds to random guessing.
📉 Results
Without access to temporal information, models perform close to random. Adding timestamps yields only modest improvements, with no model exceeding roughly 65% alignment. Even when explicit elapsed-time values are provided, the gains remain minimal. This indicates that current models struggle not only to reason about time, but also to use it effectively for decision-making.
🔍 Failure Modes
Several consistent failure patterns emerge. Models exhibit strong and inconsistent tool-use biases: some overuse tools, while others avoid them. When timestamps are provided, many models simply increase tool usage across all cases rather than selectively adjusting behavior.
Conversation length also affects behavior. As the number of turns increases, models are more likely to call tools, suggesting that they use turn count as a crude proxy for staleness instead of reasoning about actual time.
Reasoning does not resolve these issues. Chain-of-thought provides little improvement, and temporal information rarely appears in reasoning traces. This suggests that models possess temporal reasoning capabilities but fail to activate them in practice.
Finally, there is a notable mismatch between reasoning and final decisions. Models may internally conclude that a tool call is (or is not) necessary, yet produce the opposite action, further degrading alignment.
🛠️ Alignment
Prompt-based interventions are largely ineffective. Simple reminders about time have no impact, and even structured few-shot prompts only help the strongest reasoning models.
In contrast, post-training with preference optimization (DPO) yields substantial improvements across models. This demonstrates that temporal alignment is not something models can reliably infer from prompts alone—it must be learned through training.
💡 Key Insights
The paper reframes tool use as a temporal decision problem. Current LLM agents do not reliably incorporate time into their reasoning, leading to systematic inefficiencies and errors. Importantly, reasoning ability alone does not guarantee temporal awareness, and prompt engineering is insufficient to fix the issue.
A well-aligned agent should not only ask “Do I know this?” but also “Is this information still valid?”
🔗 Links
- 📄 Paper: arXiv:2510.23853
- 🤗 Dataset: TicToc Dataset
- 💻 Code: GitHub Repository
📌 Citation
@article{cheng2026temporallyblind,
title={Your LLM Agents are Temporally Blind: The Misalignment Between Tool Use Decisions and Human Time Perception},
author={Cheng, Yize and Soltani Moakhar, Arshia and Fan, Chenrui and Hosseini, Parsa and Faghih, Kazem and Sodagar, Zahra and Wang, Wenxiao and Feizi, Soheil},
journal={arXiv preprint arXiv:2510.23853},
year={2026}
}
